Exercice 1 (6 points)
Cet exercice porte sur les arbres binaires et la programmation Python dans le contexte du codage de Shannon-Fano.
Partie A
Pour obtenir le mot binaire qui encode le caractère espace, représenté par le symbole
_, il faut parcourir l’arbre de la Figure 1 de la racine jusqu’à la feuille contenant ce symbole.- On part de la racine et on prend la branche de droite, étiquetée
0. - Du nœud suivant, on prend la branche de gauche, étiquetée
1. - Du nœud suivant, on prend la branche de droite, étiquetée
0. On arrive à la feuille_.
Le mot binaire correspondant est donc
010.- On part de la racine et on prend la branche de droite, étiquetée
Pour décoder le mot binaire
0001110101111110011001, on parcourt l’arbre depuis la racine pour chaque symbole.00: racine -> droite (0) -> droite (0) -> feuillee.- Il reste
01110101111110011001. On repart de la racine. 011: racine -> droite (0) -> gauche (1) -> gauche (1) -> feuilles.- Il reste
1010111110011001. On repart de la racine. 1010: racine -> gauche (1) -> droite (0) -> gauche (1) -> droite (0) -> feuillep.- Il reste
11110011001. On repart de la racine. 1111: racine -> gauche (1) -> gauche (1) -> gauche (1) -> gauche (1) -> feuillei.- Il reste
110011001. On repart de la racine. 11001: racine -> gauche (1) -> gauche (1) -> droite (0) -> droite (0) -> gauche (1) -> feuilleo.- Il reste
1001. On repart de la racine. 1001: racine -> gauche (1) -> droite (0) -> droite (0) -> gauche (1) -> feuillen.
Le texte décodé est
espion.Pour obtenir les symboles classés par taille d’encodage croissante, il faut lister les symboles en fonction de leur profondeur dans l’arbre. Les symboles les plus proches de la racine ont les codes les plus courts. Le parcours qui explore un arbre niveau par niveau est le parcours en largeur.
Un parcours en largeur (ou Breadth-First Search, BFS) explore un arbre niveau par niveau. On visite d’abord la racine, puis tous ses enfants, puis tous les nœuds du niveau suivant, et ainsi de suite. Ce parcours est souvent mis en œuvre à l’aide d’une file.
Partie B
L’étape 2 de l’algorithme de Shannon-Fano consiste à séparer la liste ordonnée des symboles en deux groupes dont les sommes des occurrences sont les plus proches possibles.
Le tableau des symboles triés par nombre d’occurrences est :
i(1), u(1), c(1), o(1), d(1), ,(1), p(1), n(2), j(2), s(3), _(4), e(4). La somme totale des occurrences est : \(7 \times 1 + 2 \times 2 + 1 \times 3 + 2 \times 4 = 7 + 4 + 3 + 8 = 22\).Il faut donc chercher une coupure qui sépare ce total en deux sommes aussi proches que possible de \(22 / 2 = 11\).
La figure 2 propose la coupure suivante :
- Groupe 1 (gauche) :
i, u, c, o, d, ,, p, n, j. La somme de leurs occurrences est : \(1+1+1+1+1+1+1+2+2 = 11\). - Groupe 2 (droite) :
s, _, e. La somme de leurs occurrences est : \(3+4+4 = 11\).
Les deux sommes étant égales à 11, cette séparation est optimale. La justification est donc validée par ce calcul.
- Groupe 1 (gauche) :
La hauteur d’un arbre est la longueur du plus long chemin de la racine à une feuille. Dans la figure 3, les feuilles les plus profondes sont
oetd. Le chemin pour atteindredest1 -> 0 -> 1 -> 1 -> 0. Ce chemin est de longueur 5.La hauteur de l’arbre est 5.
Dans le contexte de l’exercice, cette hauteur représente la longueur du plus long mot de code binaire utilisé pour encoder un symbole.
Pour justifier que le codage de Shannon-Fano est plus efficace que l’ASCII pour le texte
je pense, donc je suis, nous devons comparer le nombre total de bits nécessaires dans chaque cas.Codage ASCII : Le texte contient 22 caractères (en se basant sur la somme des occurrences du tableau de la page 3). En ASCII, chaque caractère est codé sur un octet, soit 8 bits. Taille totale en ASCII = \(22 \text{ caractères} \times 8 \text{ bits/caractère} = 176 \text{ bits}\).
Codage de Shannon-Fano : On utilise les longueurs de code données par la profondeur de chaque symbole dans l’arbre de la figure 3 et les fréquences du tableau.
- Profondeur 2 :
e(4),_(4). Coût : \((4+4) \times 2 = 16\) bits. - Profondeur 3 :
s(3). Coût : \(3 \times 3 = 9\) bits. - Profondeur 4 :
j(2),n(2),p(1),c(1),u(1),i(1). Coût : \((2+2+1+1+1+1) \times 4 = 8 \times 4 = 32\) bits. - Profondeur 5 :
,(1),d(1),o(1). Coût : \((1+1+1) \times 5 = 3 \times 5 = 15\) bits.
Taille totale Shannon-Fano = \(16 + 9 + 32 + 15 = 72\) bits.
- Profondeur 2 :
Comparaison :
Le rapport des tailles est \(\frac{\text{Taille ASCII}}{\text{Taille Shannon-Fano}} = \frac{176}{72} \approx 2,44\). Le codage de Shannon-Fano utilise donc bien environ deux fois moins de bits (et donc d’octets) que le codage ASCII pour ce texte.
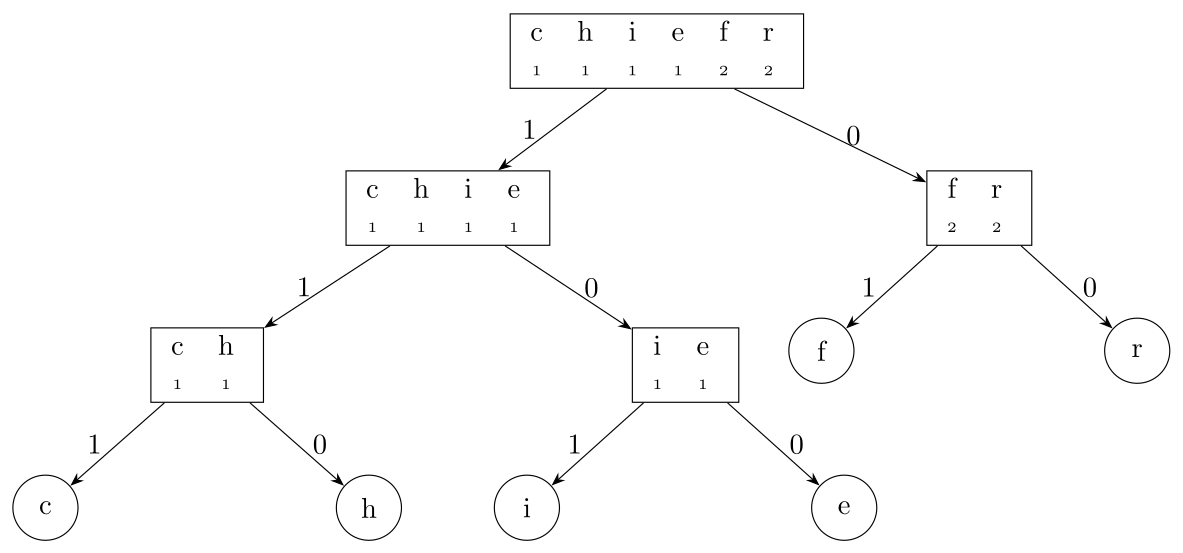
Pour construire l’arbre de codage du mot « chiffrer » :
Fréquences :
c(1), h(1), i(1), e(1), f(2), r(2). Total : 8.Liste triée :
(c,1), (h,1), (i,1), (e,1), (f,2), (r,2).Construction récursive :
Étape 1 : Somme totale = 8. On coupe en deux groupes de somme 4.
- Groupe 1 (étiquette
1):(c,1), (h,1), (i,1), (e,1). Somme = 4. - Groupe 2 (étiquette
0):(f,2), (r,2). Somme = 4.
- Groupe 1 (étiquette
Étape 2 (sur Groupe 1) : Somme = 4. On coupe en deux groupes de somme 2.
- Groupe 1.1 (
1):(c,1), (h,1). - Groupe 1.2 (
0):(i,1), (e,1).
- Groupe 1.1 (
Étape 3 (sur Groupe 1.1) :
- Feuille
c(étiquette1). Code:111. - Feuille
h(étiquette0). Code:110.
- Feuille
Étape 4 (sur Groupe 1.2) :
- Feuille
i(étiquette1). Code:101. - Feuille
e(étiquette0). Code:100.
- Feuille
Étape 5 (sur Groupe 2) :
- Feuille
f(étiquette1). Code:01. - Feuille
r(étiquette0). Code:00.
- Feuille
L’arbre de codage obtenu est le suivant :
Partie C
Voici les lignes 8 et 10 complétées pour la fonction
creer_dico_occ:# ... 7 if symbole in dico: 8 dico[symbole] += 1 9 else: 10 dico[symbole] = 1 # ...Voici une proposition pour la fonction
somme_occ:def somme_occ(tab): """ Renvoie la somme des nombres d'occurrences contenus dans un tableau de tuples (symbole, nb_occ). """ somme = 0 for symbole, nb in tab: somme += nb return sommeUne écriture plus concise utilisant une compréhension de liste est aussi possible :
def somme_occ(tab): return sum([nb for symbole, nb in tab])Voici les lignes 9 et 11 complétées pour la fonction
shannon:# ... 8 if symbole in [elt[0] for elt in t1]: 9 return "1" + shannon(symbole, t1) 10 else: 11 return "0" + shannon(symbole, t2)La terminaison de la fonction récursive
shannonest garantie par deux points :- Cas de base : La fonction s’arrête lorsque la condition
len(tab) == 1est vraie. - Convergence : À chaque appel récursif, la fonction
separedivise le tableautaben deux sous-tableaux non videst1ett2. La taille du tableau passé en paramètre à l’appel suivant (t1out2) est donc strictement inférieure à la taille du tableautabde l’appel courant. La taille de l’argument décroissant strictement à chaque étape, elle atteindra nécessairement la valeur 1, ce qui déclenchera le cas de base et mettra fin à la récursion.
- Cas de base : La fonction s’arrête lorsque la condition
Pour qu’une fonction récursive se termine, elle doit comporter :
- Un ou plusieurs cas de base qui ne génèrent pas d’appel récursif.
- Un ou plusieurs cas récursifs où la fonction s’appelle elle-même avec des arguments qui la rapprochent systématiquement d’un cas de base. On appelle cela le variant de boucle (ou de récursion) : une quantité entière positive qui décroît strictement à chaque appel.
Voici une proposition pour la fonction
encode_shannon:def encode_shannon(texte): """ Prend un texte en paramètre et renvoie le mot binaire correspondant après encodage par l'algorithme de Shannon-Fano. """ if not texte: return "" dico_occurrences = creer_dico_occ(texte) tableau_trie = creer_tab_trie(dico_occurrences) mot_binaire_final = "" for caractere in texte: code_caractere = shannon(caractere, tableau_trie) mot_binaire_final += code_caractere return mot_binaire_final
Exercice 2 (6 points)
Cet exercice porte sur les bases de données relationnelles, le langage SQL et la programmation Python.
- L’attribut
nomne peut pas être utilisé comme clé primaire pour la relationadherentcar il n’assure pas l’unicité de chaque enregistrement. Plusieurs personnes peuvent avoir le même nom de famille (homonymes). La clé primaire doit être un identifiant unique pour chaque adhérent.
Une clé primaire (primary key) est un attribut ou un ensemble d’attributs qui permet d’identifier de manière unique chaque enregistrement (ou ligne) dans une table. Sa valeur doit être unique pour chaque ligne et ne peut pas être NULL.
La requête SQL
SELECT nomJeu, editeur FROM jeu ORDER BY nomJeu;a pour effet de :- Sélectionner les colonnes
nomJeuetediteurde la tablejeu. - Trier les résultats obtenus par ordre alphabétique croissant en se basant sur la colonne
nomJeu.
Cette requête renvoie donc la liste de tous les jeux et de leur éditeur, classée par ordre alphabétique des noms de jeu.
- Sélectionner les colonnes
Pour connaître le nom des jeux en cours d’emprunt, il faut sélectionner les jeux dans la table
empruntdont l’attributdateRendua la valeurNULL. Comme un jeu ne peut être emprunté qu’une seule fois à un instant donné (un seul exemplaire), l’utilisation deDISTINCTest facultative mais reste une bonne pratique.SELECT nomJeu FROM emprunt WHERE dateRendu IS NULL;
En SQL, NULL représente une valeur inconnue ou absente. Pour tester si une colonne a la valeur NULL, on doit utiliser les opérateurs IS NULL ou IS NOT NULL, et non l’opérateur d’égalité =.
Pour afficher le nom et le prénom des adhérents ayant emprunté le jeu “Catan”, il faut lier les tables
adherentetempruntvia leur clé commune (idAdherent).SELECT adherent.nom, adherent.prenom FROM adherent JOIN emprunt ON adherent.idAdherent = emprunt.idAdherent WHERE emprunt.nomJeu = 'Catan';
Une jointure (clause JOIN) permet de combiner des lignes de deux ou plusieurs tables en se basant sur une colonne commune entre elles. La clause ON spécifie la condition de jointure.
Pour mettre à jour la base de données après le retour du jeu, il faut utiliser une requête
UPDATEpour renseigner ladateRendude l’emprunt concerné, identifié par sonidEmprunt.UPDATE emprunt SET dateRendu = '2025-06-03' WHERE idEmprunt = 1538;Pour trouver le nom et la catégorie des jeux sortis à partir de 2010 et dont l’âge minimum est strictement inférieur à 10 ans, on utilise une clause
WHEREavec deux conditions reliées par l’opérateurAND.SELECT nomJeu, categorie FROM jeu WHERE anneeSortie >= 2010 AND ageMinimum < 10;La table
participationsert à lier les événements aux adhérents. Il s’agit d’une table de jointure pour une relation de type “plusieurs à plusieurs” (un adhérent peut participer à plusieurs événements, un événement accueille plusieurs adhérents). Elle doit donc contenir une clé étrangère vers la tableevenementet une clé étrangère vers la tableadherent.La clé primaire de la table
evenementestnom, les clés étrangères de la tableparticipationsont :#nomEvenementqui fait référence à l’attributnomde la tableevenement.#idAdherentqui fait référence à l’attributidAdherentde la tableadherent.
Le script Python suivant reprend le code fourni, récupère la liste des jeux empruntés et construit le dictionnaire
dict_empruntsqui associe à chaque nom de jeu son nombre total d’emprunts.import sqlite3 # Connexion à la base de données connection = sqlite3.connect("ludotheque.db") curseur = connection.cursor() # Exécution de la requête curseur.execute("SELECT nomJeu FROM emprunt") # Récupération des résultats # curseur.fetchall() renvoie une liste de tuples, ex: [('Catan',), ('Agricola',)] jeux_empruntes_tuples = curseur.fetchall() # Création de la liste des noms de jeux liste_jeux = [] for jeu_tuple in jeux_empruntes_tuples: liste_jeux.append(jeu_tuple[0]) # Création du dictionnaire des occurrences dict_emprunts = {} for nom_jeu in liste_jeux: if nom_jeu in dict_emprunts: dict_emprunts[nom_jeu] += 1 else: dict_emprunts[nom_jeu] = 1 # Affichage du dictionnaire (pour vérification) print(dict_emprunts) # Fermeture de la connexion curseur.close() connection.close()
# On suppose que dict_emprunts est déjà créé.
dict_emprunts = {
"Terraforming Mars": 25,
"Codenames": 22,
"Agricola": 18,
"Puerto Rico": 18,
"Caylus": 18,
"Dominion": 22,
"Dixit": 12
}
# --- Étape 1 : Regrouper les jeux par score dans un dictionnaire ---
# (Cette étape reste identique et très utile)
scores_podium = {}
for jeu, score in dict_emprunts.items():
if score not in scores_podium:
scores_podium[score] = []
scores_podium[score].append(jeu)
# --- Étape 2 : Trouver les 3 meilleurs scores en cherchant le maximum 3 fois ---
# On récupère la liste des scores uniques à traiter.
scores_a_traiter = list(scores_podium.keys())
# On va stocker les listes du podium dans l'ordre où on les trouve (du meilleur au moins bon).
podium_ordre_inverse = []
# On répète l'opération 3 fois pour les 3 places du podium.
# On vérifie aussi qu'il reste des scores à traiter.
for i in range(3):
if len(scores_a_traiter) == 0:
break # Arrête la boucle s'il y a moins de 3 scores uniques.
# On cherche le score le plus élevé parmi ceux qui restent.
score_maximum = -1 # On initialise avec une valeur très basse
for score in scores_a_traiter:
if score > score_maximum:
score_maximum = score
# On ajoute la liste des jeux correspondants à notre podium temporaire.
podium_ordre_inverse.append(scores_podium[score_maximum])
# On retire ce score de la liste pour ne pas le retrouver au tour suivant.
scores_a_traiter.remove(score_maximum)
# --- Étape 3 : Inverser la liste pour avoir le podium dans l'ordre croissant des scores ---
# podium_ordre_inverse contient [liste_score_25, liste_score_22, liste_score_18]
# L'énoncé veut [liste_score_18, liste_score_22, liste_score_25]
podium_final = []
# On parcourt la liste temporaire de la fin vers le début.
for i in range(len(podium_ordre_inverse) - 1, -1, -1):
podium_final.append(podium_ordre_inverse[i])
# Affichage du podium final
print(podium_final)
# Affiche : [['Agricola', 'Puerto Rico', 'Caylus'], ['Codenames', 'Dominion'], ['Terraforming Mars']]Exercice 3 (8 points)
Cet exercice porte sur la programmation Python, la sécurisation des communications et les réseaux.
Partie A - La méthode du masque jetable
Pour chiffrer le message
LIBREavec la cléEYQMT, on suit la méthode décrite :- Convertir les lettres en rangs (de 0 à 25).
- Additionner les rangs du message et de la clé.
- Appliquer le modulo 26 au résultat.
- Reconvertir les rangs obtenus en lettres.
| Opération | L | I | B | R | E |
|---|---|---|---|---|---|
| Rang du message | 11 | 8 | 1 | 17 | 4 |
| Clé | E | Y | Q | M | T |
| Rang de la clé | 4 | 24 | 16 | 12 | 19 |
| Somme | 15 | 32 | 17 | 29 | 23 |
| Somme mod 26 | 15 | 6 | 17 | 3 | 23 |
| Lettre chiffrée | P | G | R | D | X |
Le message chiffré est PGRDX.
La fonction
indicepeut être écrite en utilisant la méthode.index()des listes en Python.def indice(element, L): """ Renvoie l'indice de element dans la liste L. """ return L.index(element)Autre solution possible, plus simple :
def indice(element, L): """ Renvoie l'indice de element dans la liste L. """ for i in range(len(L)): if L[i] == element: return i return -1 # Si l'élément n'est pas trouvé, on renvoie -1.La fonction
lettres_vers_indicesparcourt la chaîne de caractères et utilise la liste globalealphabetpour trouver l’indice de chaque lettre.# On suppose que la variable 'alphabet' est définie globalement. alphabet = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'] def lettres_vers_indices(chaine): """ Renvoie la liste des indices des caractères de la chaîne. """ indices = [] for caractere in chaine: indices.append(indice(caractere, alphabet)) return indices # Une version plus concise avec une liste en compréhension : # def lettres_vers_indices(chaine): # return [indice(c, alphabet) for c in chaine]Voici le code complété de la fonction
chiffrement.def chiffrement(msg, cle): assert len(cle) >= len(msg), 'impossible' indices_msg = lettres_vers_indices(msg) indices_cle = lettres_vers_indices(cle) n = len(msg) indices_msg_chiffre = [] for k in range(n): # Ligne 8 : Addition des indices du message et de la clé ind = indices_msg[k] + indices_cle[k] # Ligne 9 : Application du modulo 26 si nécessaire if ind >= 26: # Ligne 10 : L'opération est une soustraction de 26 ind = ind - 26 indices_msg_chiffre.append(ind) # Ligne 12 : Conversion de la liste d'indices en chaîne de caractères msg_chiffre = indices_vers_lettres(indices_msg_chiffre) # Ligne 13 return msg_chiffreLors de l’appel
chiffrement('RESEAU', 'GFTZ'), la condition de l’instructionassertest évaluée.len('RESEAU')vaut 6 etlen('GFTZ')vaut 4. La conditionlen(cle) >= len(msg)(soit4 >= 6) est fausse.L’exécution du programme s’arrête et une erreur de type
AssertionErrorest levée, affichant le message'impossible'.Pour déchiffrer
GMEDHavec la cléFVEIT, on effectue l’opération inverse : la soustraction modulo 26. \(C_{dechiffré} = (C_{chiffré} - C_{clé}) \pmod{26}\).
| Opération | G | M | E | D | H |
|---|---|---|---|---|---|
| Rang chiffré | 6 | 12 | 4 | 3 | 7 |
| Clé | F | V | E | I | T |
| Rang de la clé | 5 | 21 | 4 | 8 | 19 |
| Différence | 1 | -9 | 0 | -5 | -12 |
| Différence mod 26 | 1 | 17 | 0 | 21 | 14 |
| Lettre déchiffrée | B | R | A | V | O |
Le message déchiffré est BRAVO.
Pour déchiffrer un message, il faut effectuer l’opération mathématique inverse de celle du chiffrement. Le chiffrement est une addition modulo 26. Son inverse est donc une soustraction modulo 26.
Pour chaque caractère, on soustrait le rang de la lettre de la clé au rang de la lettre du message chiffré, et on prend le résultat modulo 26.
Mathématiquement : si \(Chiffré = (Message + Clé) \pmod{26}\), alors \(Message = (Chiffré - Clé) \pmod{26}\).
Pour obtenir la fonction
dechiffrement, on adapte la fonctionchiffrementen remplaçant l’addition par une soustraction.def dechiffrement(msg_chiffre, cle): assert len(cle) >= len(msg_chiffre), 'impossible' indices_msg = lettres_vers_indices(msg_chiffre) indices_cle = lettres_vers_indices(cle) n = len(msg_chiffre) # Ligne 6 adaptée indices_msg_dechiffre = [] for k in range(n): # Ligne 8 adaptée : Soustraction des indices ind = indices_msg[k] - indices_cle[k] # Ligne 9 adaptée : Gestion des résultats négatifs if ind < 0: # Ligne 10 adaptée : Ajout de 26 ind = ind + 26 indices_msg_dechiffre.append(ind) # Ligne 12 adaptée msg_dechiffre = indices_vers_lettres(indices_msg_dechiffre) # Ligne 13 adaptée return msg_dechiffre
Partie B - Sécurisation des communications
La différence fondamentale entre un algorithme de chiffrement symétrique et asymétrique réside dans la gestion des clés :
- Chiffrement symétrique : utilise une seule et même clé secrète pour chiffrer et déchiffrer le message. Cette clé doit être partagée de manière sécurisée entre l’émetteur et le destinataire avant la communication.
- Chiffrement asymétrique : utilise une paire de clés pour chaque utilisateur : une clé publique, que l’on peut distribuer librement, et une clé privée, qui doit rester secrète. Ce qui est chiffré avec la clé publique ne peut être déchiffré qu’avec la clé privée correspondante.
Alice chiffre son message avec la clé publique de Bob. Pour déchiffrer le message reçu, Bob utilise sa clé privée, qui est la seule capable d’inverser l’opération de chiffrement effectuée par sa clé publique.
Dans le scénario décrit, n’importe qui (une tierce personne, Eve par exemple) peut obtenir la clé publique de Bob. Eve peut alors chiffrer un message avec cette clé et l’envoyer à Bob en se faisant passer pour Alice. Bob pourra déchiffrer le message, mais n’aura aucun moyen de vérifier que l’expéditeur est bien Alice. Ce protocole simple ne garantit pas l’authentification de l’émetteur.
HTTPS (HyperText Transfer Protocol Secure) est la version sécurisée du protocole HTTP. Il combine HTTP avec un protocole de sécurité comme TLS (Transport Layer Security). HTTPS assure trois garanties de sécurité principales :
- Confidentialité : Les données échangées sont chiffrées, les rendant illisibles pour un attaquant qui les intercepterait.
- Intégrité : Les données ne peuvent pas être modifiées durant leur transit sans que la modification soit détectée.
- Authentification : Il permet de vérifier l’identité du serveur web auquel on se connecte, grâce à un système de certificats numériques.
On utilise le protocole HTTPS (qui est un système hybride) plutôt qu’un chiffrement purement asymétrique pour des raisons de performance. Le chiffrement asymétrique est beaucoup plus lent et gourmand en ressources de calcul que le chiffrement symétrique. Il est donc mal adapté pour chiffrer de grandes quantités de données. HTTPS utilise le chiffrement asymétrique uniquement au début de la connexion pour authentifier le serveur et négocier une clé de session secrète. Ensuite, toute la communication est chiffrée avec un algorithme symétrique, beaucoup plus rapide, utilisant cette clé de session.
Partie C - Réseaux
L’affichage
100% packet lossindique que la machine de Marc a envoyé 4 paquetspingà l’adresse IP192.168.100.115, mais n’a reçu aucune réponse. L’erreur de Marc est une faute de frappe dans l’adresse IP du poste de Bob. L’adresse correcte est192.168.110.115. Marc a tapé100au lieu de110dans le troisième octet. Il a donc tenté de contacter une machine sur un autre réseau (192.168.100.0/24), qui est probablement inaccessible depuis son poste.Pour obtenir la représentation décimale du masque
11111111.11111111.11111111.11100000, on convertit chaque octet binaire en décimal :11111111en binaire correspond à \(2^8-1 = 255\) en décimal.11100000en binaire correspond à \(1 \times 2^7 + 1 \times 2^6 + 1 \times 2^5 = 128 + 64 + 32 = 224\) en décimal.
Le masque de sous-réseau en décimal est
255.255.255.224.Le masque
255.255.255.224a 27 bits à 1 pour la partie réseau (\(8+8+8+3=27\)). La partie hôte est donc sur les \(32 - 27 = 5\) bits restants. Le nombre total d’adresses IPv4 sur ce sous-réseau est \(2^5 = \textbf{32}\).(Note : parmi ces 32 adresses, 2 sont réservées : l’adresse du sous-réseau lui-même et l’adresse de diffusion. Il y a donc \(32 - 2 = 30\) adresses attribuables à des hôtes).
Pour convertir le nombre 134 en binaire, on utilise la méthode des divisions successives par 2 ou par décomposition en puissances de 2. \(134 = 128 + 6 = 128 + 4 + 2 = 1 \cdot 2^7 + 0 \cdot 2^6 + 0 \cdot 2^5 + 0 \cdot 2^4 + 0 \cdot 2^3 + 1 \cdot 2^2 + 1 \cdot 2^1 + 0 \cdot 2^0\).
La représentation binaire de 134 sur un octet est
10000110.Pour savoir quelle commande a fonctionné, il faut déterminer si les machines cibles sont dans le même sous-réseau que Zoé. Deux machines peuvent communiquer directement si elles sont sur le même sous-réseau.
Masque :
255.255.255.224(11100000pour le dernier octet).IP de Zoé :
192.168.110.134(10000110pour le dernier octet).- Adresse du sous-réseau de Zoé :
134 ET 224->10000110 ET 11100000=10000000(soit 128). Le sous-réseau est192.168.110.128.
- Adresse du sous-réseau de Zoé :
Commande n°1 :
ping 192.168.110.115(Bob)- Le dernier octet de l’IP de Bob est 115 (
01110011). - Adresse du sous-réseau de Bob :
115 ET 224->01110011 ET 11100000=01100000(soit 96). Le sous-réseau est192.168.110.96.
- Le dernier octet de l’IP de Bob est 115 (
Commande n°2 :
ping 192.168.110.153(Marc)- Le dernier octet de l’IP de Marc est 153 (
10011001). - Adresse du sous-réseau de Marc :
153 ET 224->10011001 ET 11100000=10000000(soit 128). Le sous-réseau est192.168.110.128.
- Le dernier octet de l’IP de Marc est 153 (
Conclusion : Zoé et Marc sont sur le même sous-réseau (
192.168.110.128), alors que Bob est sur un sous-réseau différent (192.168.110.96). La communication directe est possible entre Zoé et Marc.C’est donc la commande n°2 qui a produit l’affichage indiquant une réussite de la communication.